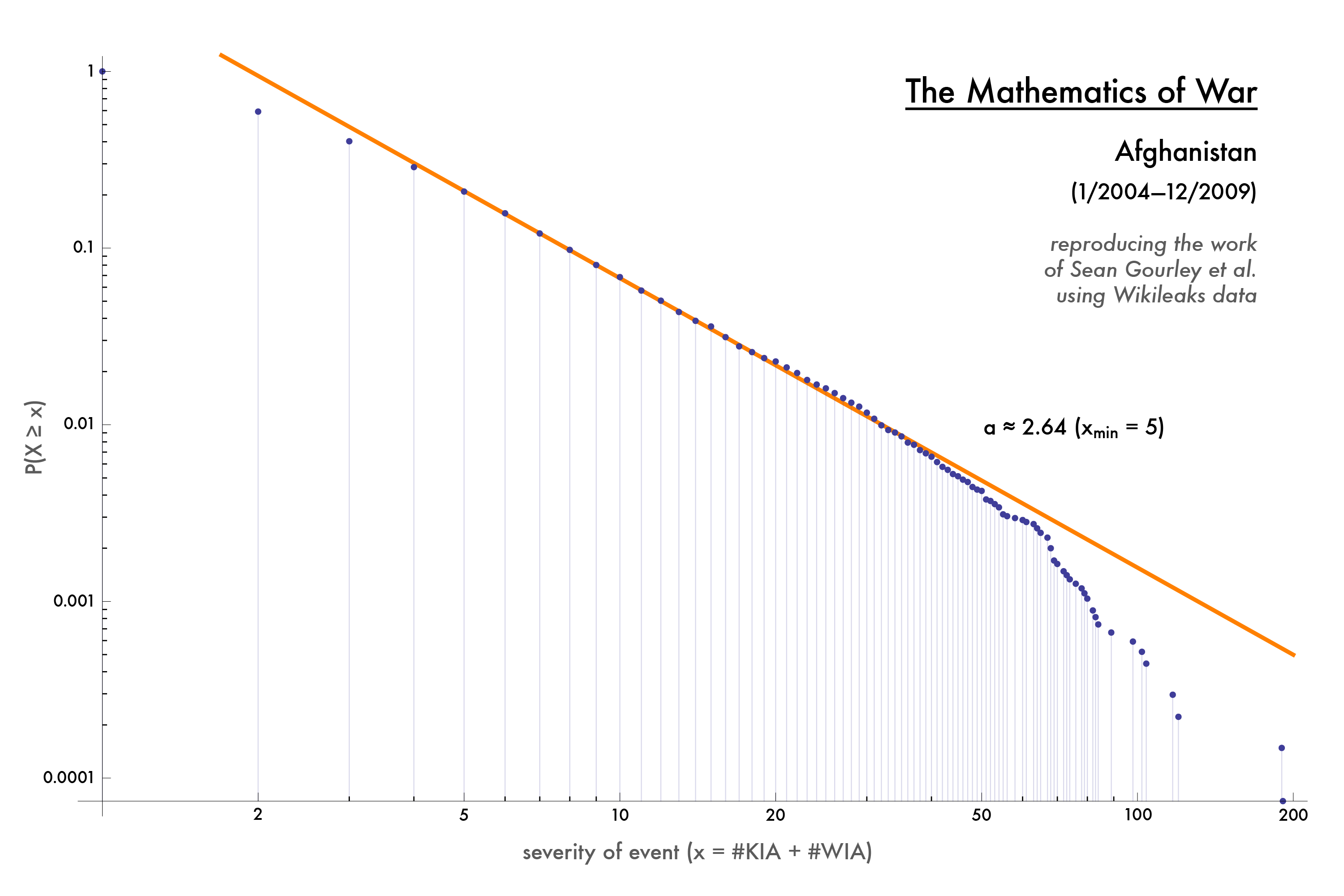
Guest post by Idean Salehyan and Henrik Urdal

Quality data is at the heart of quality research. The scholarly community depends on valid, reliable, and easily accessible data in order to empirically test our theories of social and political processes. Yet quantitative data is not “truth” in an absolute sense, but rather, is a numeric representation of complex phenomena. For conflict researchers, the challenge of collecting quality data is particularly acute given the nature of our enterprise. Given the costs and risks involved, it is practically impossible to observe every battle, civilian massacre, human rights violation, or protest event. Therefore, we often rely upon other sources—journalists, non-governmental organizations, truth commissions, and so on—to report on key features of a conflict, then turn such information into numeric values. Turning such reports into data isn’t a trivial task, but requires digesting large amounts of text, sorting through often-conflicting information, making judgments about coding rules, and dealing with ambiguous cases.
Recently, there have been a number of conversations in the conflict studies community about the challenge of collecting data that is accurate, replicable, and inter-operable with existing data. One such discussion occurred during a workshop held at the 2013 Annual Meeting of the International Studies Association in San Francisco, where several key figures from leading data collection projects were gathered. Some of the key concepts and ideas from that workshop were recently turned into a series of short articles, just published as a special feature of the Journal of Peace Research. In that special feature, scholars discuss their own experiences (good and bad) with collecting data, updates on current data projects, and practical tools for future data collection, all with an eye on common standards and best practices (for an exemplary discussion of best practices, see this paper by Christian Davenport and Will Moore).
What is the upshot of all this? In short, and being only a little glib, gone are the days when researchers could claim that they read several books and articles on a conflict and others had to simply “take their word” that their data are accurate. Not only should statistical results be replicable, but also, others should be able to consult the same sources, use the same coding rules, and generate data that is as close to the original as possible. This means transparency at all stages of a data collection project, opening wide the doors of the sausage factory.
First, scholars should take care to select their sources wisely. This also means that sources should be documented for each datum and this information be shared with others. The potential for missing or biased information in the sources should also be addressed, and there are increasingly sophisticated methods being developed for validating the quality of sources. All too often, researchers are not systematic about the sources used and rarely do they provide a list of references for others to fact-check the particulars of a case. As primary and secondary sources are our closest link to the “truth,” source selection is perhaps the most critical step in data collection.
Second, coding rules and procedures should be made transparent to users. This includes providing inter-coder reliability statistics, a discussion of difficult or ambiguous cases, and providing confidence estimates for individual data points. When using automated coding methods, open-source sharing of code should be standard practice. Admittedly, some coding decisions will be far simpler than others. It is easier to count the number of UN Security Council Resolutions on a conflict, for instance, than it is to estimate the number of civilian casualties. Yet, providing the rationale for arriving at a particular coding decision is a necessary part of data transparency.
Finally, data must be archived in easily accessible repositories. Spreadsheets posted on individual websites have previously been the norm, yet this approach limits the ability of others—especially those unfamiliar with the field—to easily find and access the data. Repositories such as the Interuniversity Consortium for Social and Political Research and the Dataverse project have been invaluable resources for finding and accessing data. In addition, data providers should take care so that their products can be easily merged with other related datasets, thereby facilitating cumulative research.
These themes, and others, are explored in depth in the current issue of Journal of Peace Research and we encourage people interested in data issues to browse its contents. As people embark on new data collection projects, keeping in mind a few simple principles will hopefully save a lot of headache later. Yet we need sustained, in-depth conversations such as this to advance the cause of reliable data, which is at the heart of our collective enterprise.
Now that a vast amount of information about the world is readily available at our fingertips, scholars have been able to collect an impressive array of data for analysis. Clearly, such data is an important public good for the academic community and anyone who accepts the challenges and frustrations of data collection should be commended. All too often, however, users and producers of data have been somewhat lackadaisical about standards. But because the integrity of statistical research rests on the veracity of the underlying information, it is imperative that we seriously think about how to ensure data quality.
Idean Salehyan is an Associate Professor of Political Science at the University of North Texas and Henrik Urdal is a Research Professor at the Peace Research institute Oslo and the editor of the Journal of Peace Research.




1 comment
Reblogged this on Refugee Archives @ UEL.